VIVA Integrity —
Multimodal integrity for every AI interview
VIVA Integrity is the trust layer across every Assess session. A multimodal model evaluates seven independent signals — head pose, eye gaze, no-face, multi-face, tab switches, lip sync, and code screen reading — each scored with a severity tier (Clean / Low / Medium / High) and a confidence percentage. Every flagged moment deep-links to the exact second in the recording.
Core capabilities
- Per-session Integrity score (0–100) + severity tiers
- 7 multimodal signals with timestamped moments
- Identity match at session start (webcam snapshot)
- Screen Reading detection on every coding round
What's inside VIVA Integrity
Head movement
MediaPipe head-pose model flags ≥30° pitch/yaw sustained ≥3s. Distinguishes natural posture shifts from sustained look-aways.
Eye gaze
Gaze estimation flags off-screen episodes >3s — surfaces repeated glances during technical questions for human review.
No-face & multiple-face
Face presence model flags gaps >2s; face-count model flags any co-presence sustained ≥2s. Catches candidate swaps in real time.
Tab switches
Browser focus/visibility events flag interview-tab switches >5s, cross-referenced with mouse/keyboard idle.
Lip sync
Audio-visual phoneme alignment flags drift >150ms — surfaces overdubs and AI-generated voice attempts.
Code screen reading
Semantic + token n-gram model flags ≥60% similarity to public sources, with the offending lines and suggested replacement problem.
Identity match
Webcam frame captured at session start with a 98% identity-match score against the candidate's ID.
Defensible audit trail
Tamper-evident recording, 30-day retention, exportable report, and bias-audit logs aligned to NYC Law 144 and the EU AI Act.
Frequently asked questions
Everything teams typically ask about VIVA Integrity before a demo.
Ready to see VIVA Integrity in action?
Get a 30-minute walkthrough tailored to your hiring volume and roles.
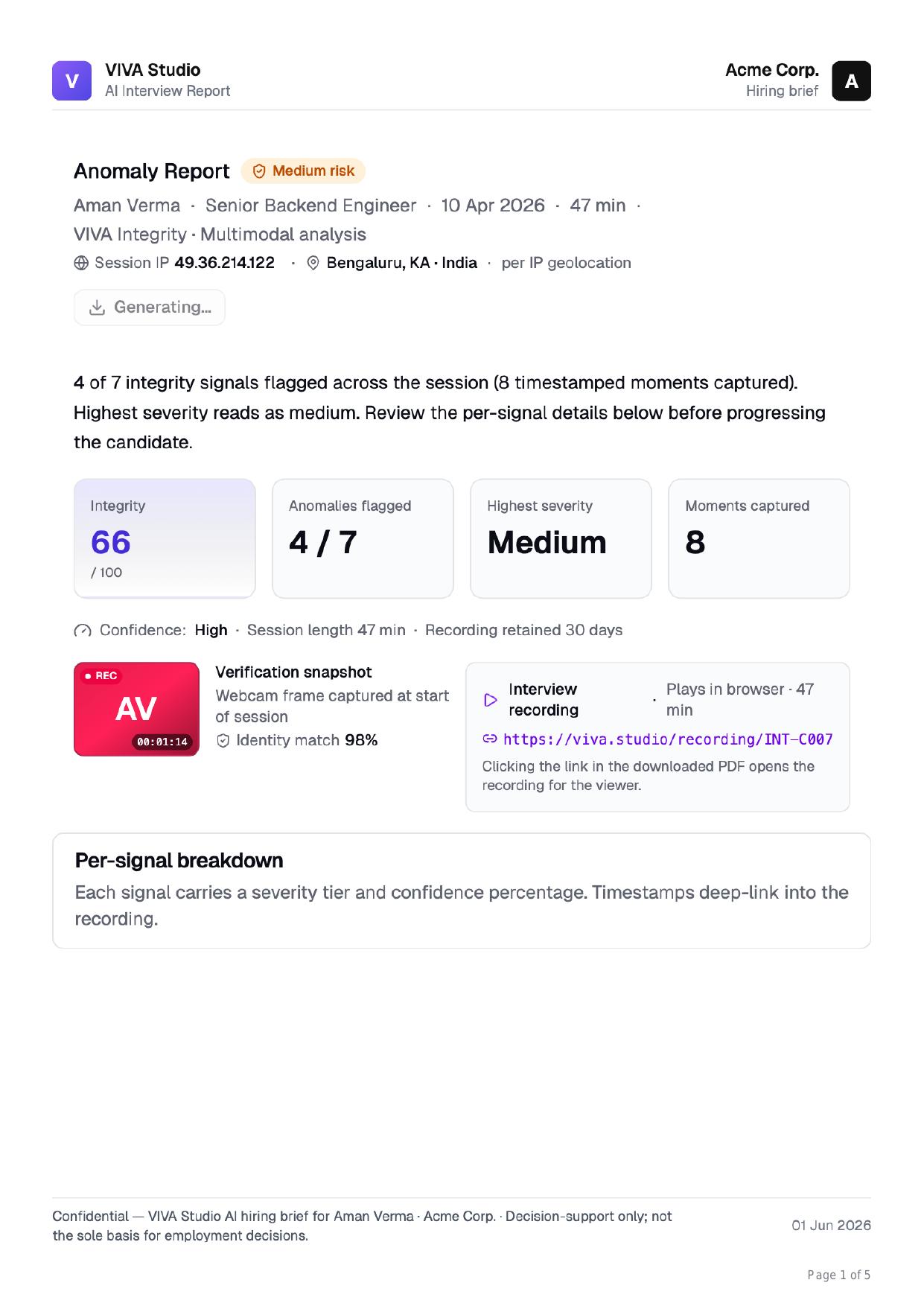
One score, every signal, every session
Each Assess session ships with an Integrity score, a count of flagged signals, the highest severity reached, and an identity-match snapshot — all on one defensible page.
- Integrity 0–100 score with Clean / Low / Medium / High tier
- Webcam identity match captured at session start (98%)
- 30-day recording retention with deep-link timestamps
Seven signals, one Integrity score
Each signal runs an independent model with its own severity tier and confidence percentage. Every flagged moment deep-links into the session recording.
Head movement
MediaPipe head-pose · ≥30° sustained ≥3s
- ▶ 00:08:42 — turned right 35° for 6s
- ▶ 00:31:17 — brief downward tilt 4s
Eye gaze
Gaze estimation · off-screen >3s
- ▶ 00:14:33 — off-screen 8s during DS probe
- ▶ 00:37:54 — glances down-left for 18s during coding
No face
Face presence · gaps >2s
Multiple faces
Face count · >1 face ≥2s
Tab switches
Browser focus events · switch >5s
- ▶ 00:18:33 — tab lost focus 8s, input idle
Lip sync
Audio-visual phoneme alignment · drift >150ms
Screen Reading
Semantic + n-gram code similarity · ≥60%
- ▶ 00:41:08 — 71% token similarity to public source
- ▶ 00:42:55 — identical variable naming
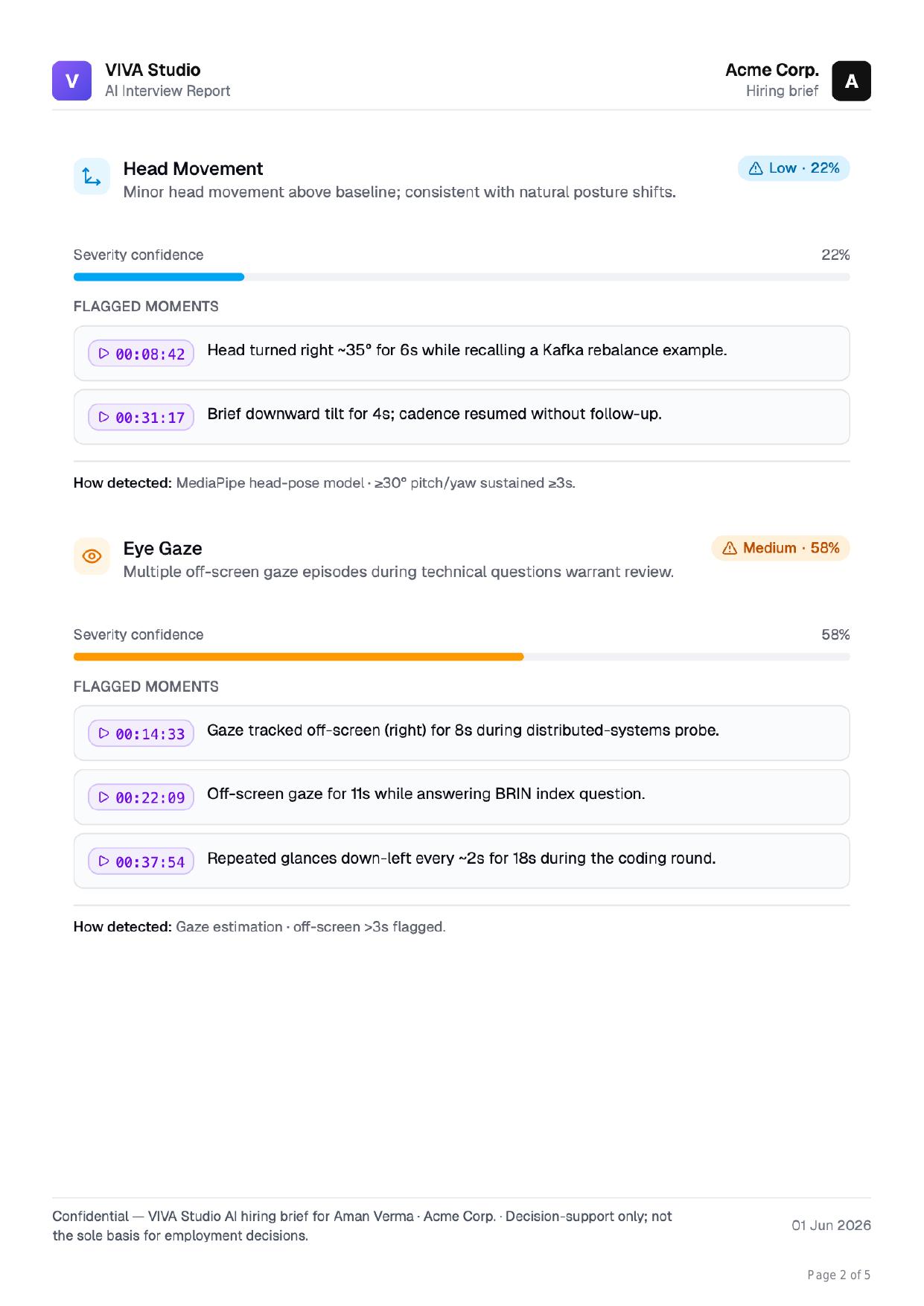
Head pose and gaze, with the exact moment
When gaze drifts off-screen for 8 seconds during a distributed-systems probe, you don't just see a flag — you get the timestamp and the question that was being asked.
- Severity tier + confidence percentage per signal
- MediaPipe head-pose and gaze-estimation models
- Each moment deep-links into the recording
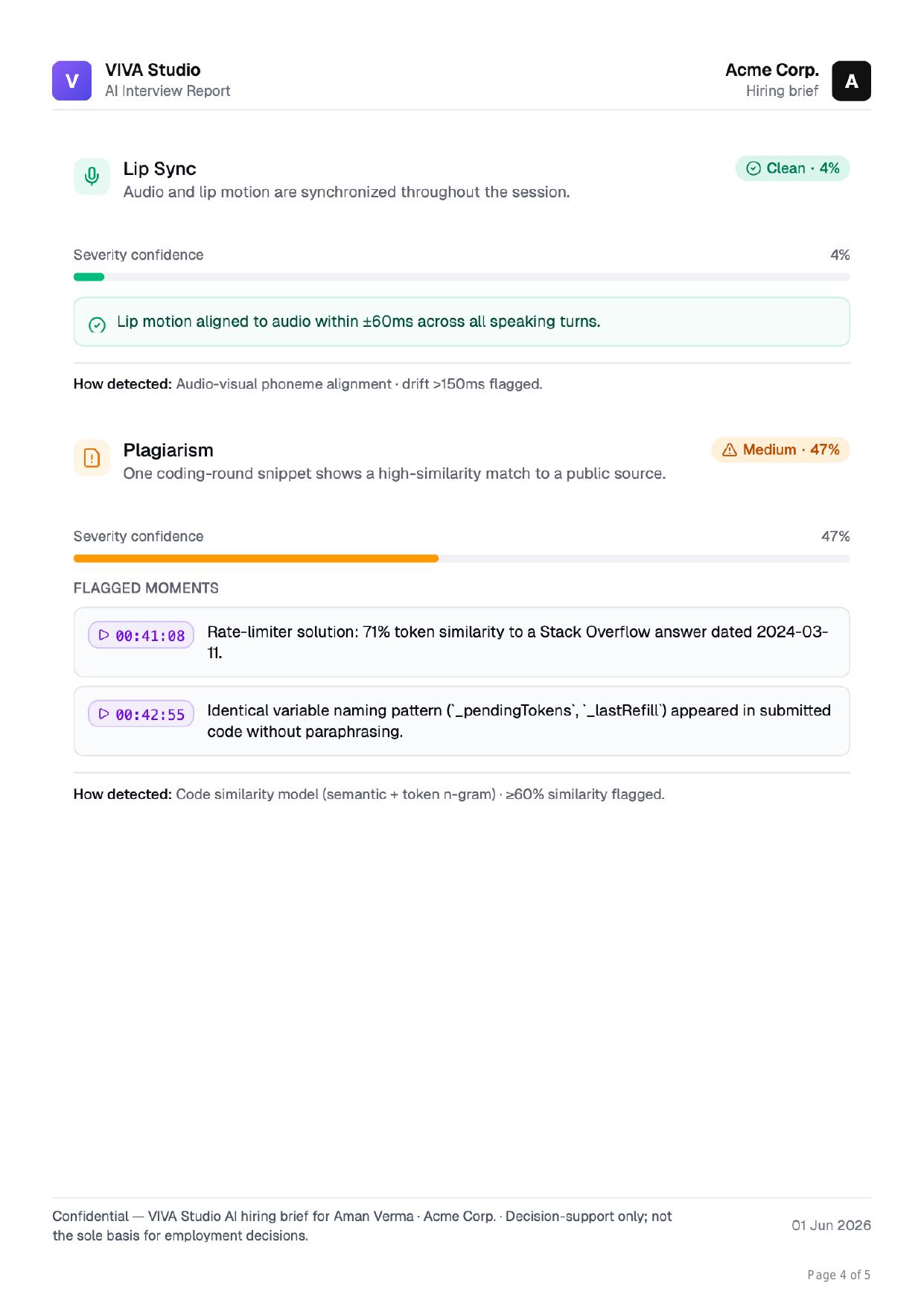
Screen Reading flagged at the line level
A semantic + n-gram model checks every coding round against public sources. When a rate-limiter answer matches a Stack Overflow snippet at 71%, you see the offending lines and a recommended replacement problem.
- Semantic + token n-gram code similarity ≥60% flagged
- Lip-sync clean check (audio-visual phoneme alignment)
- Suggested next step: re-evaluate with a private problem
A flagged signal isn't a verdict. VIVA Integrity is designed to be combined with the Interview Report before any advance-or-reject decision — every model output is explainable, bias-audited, and reviewable by a human.